De duurzame weg naar succes is: training, training, training

De duurzame weg naar succes is: training, training, training
![]()
Hamburg, Germany, 28 en 29 September 2015
Onze bijdragen aan de Data Modeling Zone 2015:
Peter Alons
PAlCon
Rob Arntz
i-refact
When we build a BI-environment, we generally aim high, creating high expectations, as very great rewards may be reaped from the investments made. For doing so, we need adequate knowledge and documentation, and an evolutionary realization in a complex and ever changing environment. That environment may be fragmented, using different codes for the same things and various operational systems for the same type of information. The source data may be offered in various types of structure or even an unstructured form, as in the case of ‘Big Data’. Therefore, we are in such projects seriously threatened with a Babylonian confusion of tongues. The standard IT-approach to cope with these problems is an attempt to set up a corporate ‘business model’ in terms of an IT-gibberish presented in the form of a database structure instead of a model understandable by the business. And as the last should be the first requirement for a good ‘business model’, this approach clearly does not unconfuse the Babylonians.
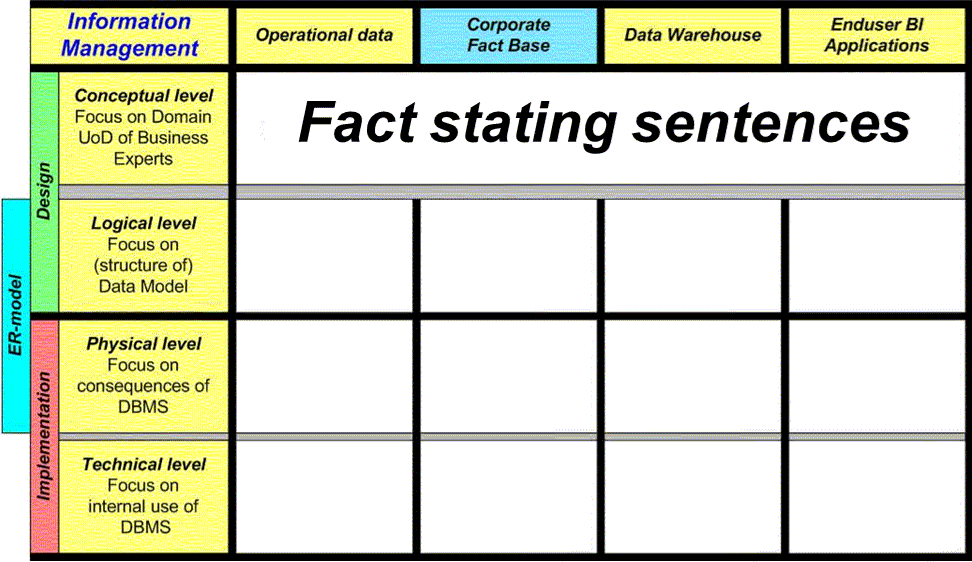
To build a useful BI-environment we need adequate data models, regardless of the nature of the sources from which the BI-information is derived. In the fully automated approach of the Information Management Frame we build such models by means of ‘Fact Oriented Modeling’. This approach stipulates the necessity of a true conceptual model, in which the focus lies on the Universe of Discourse of the true business customers of the BI-environment to be developed. All models needed for the BI-environment - whether at the logical, physical, or technical level, and whether in the form of fully normalized, star-like, or generic structures - must be derived from this conceptual model by means of mathematically sound transformations irrespective of the specific structures asked for. This stems from the fact that in the conceptual model all relevant information needed in the BI-environment is split into elementary facts, expressed in fact-stating sentences that are devoid of any non-conceptual information or constructs. These elementary facts are the true building blocks of the whole BI-environment to be built, and they remain exactly the same irrespective of the structural forms they are cast into. Therefore, it is essential that the semantics of all these facts is completely validated by the domain experts before any part of the BI-environment is built. Throughout all transformations the semantics of all facts is preserved and transferred with the new models created. This way the full design of the BI-environment is guaranteed to be perfect before, during and after the realization of all applications. And at all times the end-customers will be able to fully understand the information contents delivered by their applications.
In one hour the attendees will be initiated in the powerful approach of the Information Management Frame. The presentation will be in the form of interactive gaming with the attendees.
![]()
Hamburg, Germany, 29 en 30 September 2014
Onze bijdragen aan de Data Modeling Zone 2014:
Peter Alons
PAlCon
Rob Arntz
i-refact
A brief overview to fact-oriented data modeling. Peter and Rob presented this contribution both on Monday and on Tuesday as an introduction to a two hours case study using fact-oriented data modeling on Tuesday. For those who were new to fact-oriented data modeling, this primer ensured they would benefit from the case study.
Peter Alons
PAlCon
Rob Arntz
i-refact
“How many patients with severe sepsis were treated with the drug Drotricogen.alpha (aPC) against septic shock?” Where data modeling focuses on how data should be stored, information modeling is focusing on which information is required to answer complicated questions like this. To do so we need techniques of which the results can be validated by the information consumers themselves. Especially in very specialized environments this is crucial. The Erasmus Medical Center is such a specialized environment.
Forced by the Dutch Health Inspection, medical specialists have to find the right answers to questions like the one above, “What is the percentage of hospitalized and operated patients with at any given moment a numerical pain score above 7 in the first 72 hours after the operation?”, “What is the percentage of adult hospitalized patients admitted at the IC with severe sepsis, who died within 30 days after the diagnosis?”, and so on. For us this meant that we needed terms like hospitalized, operated, pain score, medication and dosage, and diagnosis in our information model. And then it is important to know what facts these terms exactly relate to, i.e. what their semantics are.
In this session we showed attendees how FOM is used to cast these semantics into a conceptual information model, and how this information model – validated by the medical experts – is transformed into adequate data structures by using the case tool CaseTalk™. The attendees were given the opportunity to participate actively in the modeling process. The importance of supporting this type of investigations correctly is stressed by the fact that the drug aPC is – due to the contributions of the Erasmus Medical Center – nowadays rejected as proper treatment against septic shock…